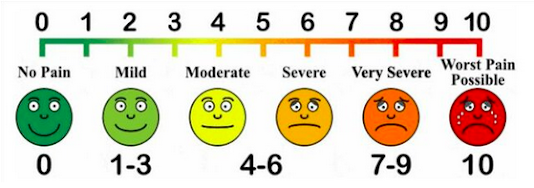
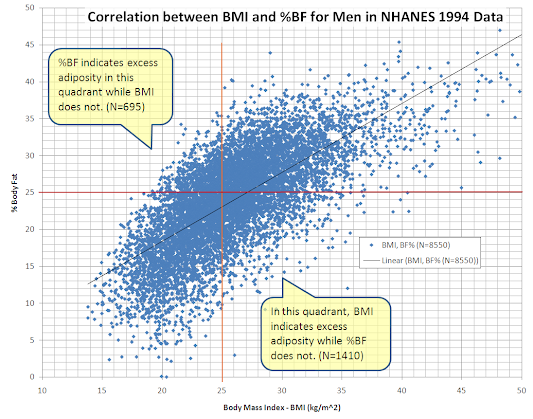
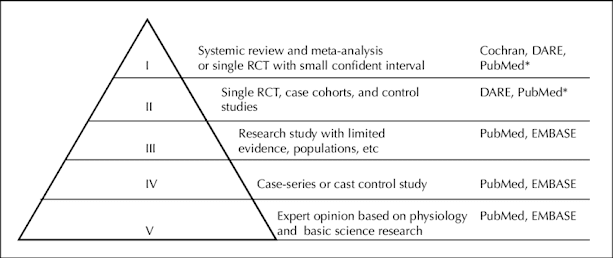
Data: raw, analysis, and presentation (part I)
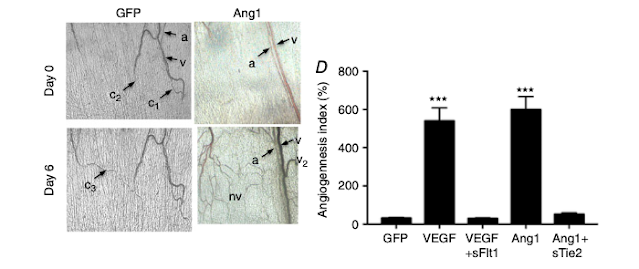
So, what did you find? You've found a research gap and developed a hypothesis 🔍🔎 You've chosen the appropriate study design to test your hypothesis ❌❎ You've collected data from the experiments you conducted 📙📀 And now? The results section is the one that conveys the importance of a manuscript, but the collected unprocessed data is raw. A bunch of numbers, quotes from surveys, or images won't give you any insight 😕 ; not if you don't have a plan for data analysis. When reporting data, it is important to be clear, brief, and accurate. And remember that the most visually appealing section of the paper must have a polished presentation. 💅 Look at all the pretty pictures and charts! I'll be illustrating the points below using examples from the results section of the research paper by Stone et al . (J Physiol . 2017;595(5):1575-1591. doi:10.1113/JP273430). Outlining and analysis My academic mentors always asked me to plan out what the figures in a manus...