Reliability
Validity and reliability are used to assess the rigour of research.
How is this evaluated?
Internal consistency: a measure of correlation, not causality. The extent to which all the items on a scale measure one construct or the same latent variable.
Depending on the type of test, internal consistency may be measured through Cronbach's alpha, Average Inter-Item, Split-Half, or Kuder-Richardson test.
Example: Visual Analog Scales and Likert Scales.
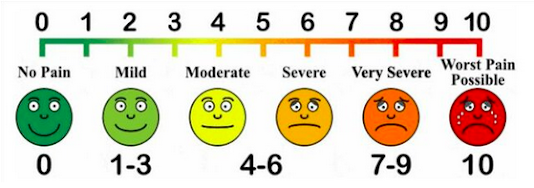
This VAS for pain is presented to participants without the numerical scale (see here). Parallel forms: the correlation between two equivalent versions of a test.
The easiest way to measure this is simply to alter the order of questions on a questionnaire, which should minimise memory, training, or habituation effects.
Test-retest reliability: is the repeatability of a test over time.
Together, these assess the stability of the measurement.
Although these scales require prior cultural adaptation and validation, in longitudinal studies they may be used to infer temporal trends —such as the secular rise in IQ test scores (Flynn Effect).
Interrater reliability: measures the degree of agreement between different people observing or assessing the same thing.
It can help mitigate observer bias, and is used when data is collected by researchers assigning ratings, scores, or categories.
In medicine, it is often used when two or more specialists provide a diagnosis based on imaging (pathological samples, tomographs, radiographs, magnetic ressonance).




Comments
Post a Comment