Validity
The aim of scientific research is to produce generalizable knowledge about the real world.
An experiment's validity is established in reference to a specific purpose —the
test or technique used may not be valid for different purposes.
However, scientists are human and fallible. The illusion of validity describes our tendency to be overconfident in the accuracy of our judgements, specifically in our interpretations and predictions regarding a given data set.
Temporal validity tests the plausibility of research findings over a given time frame. When conducting the same experiment at key points over a period of time, historical events may affect results.
The most recent example of this is the rise in cancer deaths due to untreated or undiagnosed cancers during the COVID-19 mandatory lockdown.
Population validity evaluates whether the chosen sample or cohort represents the entire population, and also whether the sampling method is acceptable.
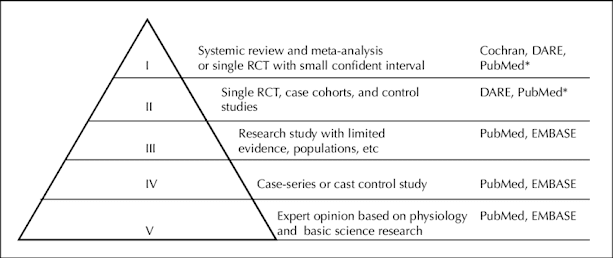
In evidence-based medicine, randomized controlled trials (RCTs) are given the highest level of evidence, because they are designed to be unbiased and have less risk of systematic errors. By randomly allocating subjects to two or more treatment groups, these types of studies also randomize confounding factors that may bias results.
Ecological validity questions the level of realism involved in the experiment and whether that impacted the authenticity of the results.
This is particularly relevant in the field of psychology because human subjects frequently react differently in different environments.

Ecological validity is a type of external validity, which measures the extent to which you can generalize the findings of a study to other situations, people, settings, and measures.
In contrast, internal validity describes the extent to which a cause-and-effect relationship established in a study cannot be explained by other factors,
For instance, the journal Bio-protocol requests that protocols include information about the number of replicates, statistical tests applied, and controls that were used in its validation.
Next time, I'll explore how face and construct validity are interlinked with biases.



Comments
Post a Comment